Context engineer
2025年10月9日
11:30
What is context engineering?
Context engineering is building dynamic systems to provide the right information and tools in the right format such that the LLM can plausibly accomplish the task.
来自 <https://blog.langchain.com/the-rise-of-context-engineering/>
在正确的时间,用正确的format提供给llm正确的信息。
Context engineering is a system
Complex agents likely get context from many sources. Context can come from the developer of the application, the user, previous interactions, tool calls, or other external data. Pulling these all together involves a complex system.
This system is dynamic
Many of these pieces of context can come in dynamically. As such, the logic for constructing the final prompt needs to be dynamic as well. It is not just a static prompt.
You need the right information
A common reason agentic systems don’t perform is they just don’t have the right context. LLMs cannot read minds - you need to give them the right information. Garbage in, garbage out.
You need the right tools
It may not always be the case that the LLM will be able to solve the task just based solely on the inputs. In these situations, if you want to empower the LLM to do so, you will want to make sure that it has the right tools. These could be tools to look up more information, take actions, or anything in between. Giving the LLM the right tools is just as important as giving it the right information.
The format matters
Just like communicating with humans, how you communicate with LLMs matters. A short but descriptive error message will go a lot further a large JSON blob. This also applies to tools. What the input parameters to your tools are matters a lot when making sure that LLMs can use them.
Can it plausibly accomplish the task? 你需要明确的是,LLM到底能不能根据提供的信息,完成任务。
This is a great question to be asking as you think about context engineering. It reinforces that LLMs are not mind readers - you need to set them up for success. It also helps separate the failure modes. Is it failing because you haven’t given it the right information or tools? Or does it have all the right information and it just messed up? These failure modes have very different ways to fix them.
来自 <https://blog.langchain.com/the-rise-of-context-engineering/>
How Long Contexts Fail https://www.dbreunig.com/2025/06/22/how-contexts-fail-and-how-to-fix-them.html
- Context Poisoning
Context Poisoning is when a hallucination or other error makes it into the context, where it is repeatedly referenced.
The Deep Mind team called out context poisoning in the Gemini 2.5 technical report, which we broke down last week. When playing Pokémon, the Gemini agent would occasionally hallucinate while playing, poisoning its context:
比如有多轮对话,其中某一轮对话可以存在幻觉,那么这个幻觉可能会随着对话的进行而继续传播。
- Context Distraction
Context Distraction is when a context grows so long that the model over-focuses on the context, neglecting what it learned during training.
In this agentic setup, it was observed that as the context grew significantly beyond 100k tokens, the agent showed a tendency toward favoring repeating actions from its vast history rather than synthesizing novel plans.
当context超长时,llm倾向于重复context中的内容,而不是采取新的行动。
- Context Confusion
当提供给llm的tool(with tool description)非常多,llm很难选择正确的tool
The Berkeley Function-Calling Leaderboard is a tool-use benchmark that evaluates the ability of models to effectively use tools to respond to prompts. Now on its 3rd version, the leaderboard shows that every model performs worse when provided with more than one tool. Further, the Berkeley team, “designed scenarios where none of the provided functions are relevant…we expect the model’s output to be no function call.” Yet, all models will occasionally call tools that aren’t relevant.
When the team gave a quantized (compressed) Llama 3.1 8b a query with all 46 tools it failed, even though the context was well within the 16k context window. But when they only gave the model 19 tools, it succeeded.
不要提供过多的tool给llm,一般10-15个是合适的。
- Context Clash
Context Clash is when you accrue new information and tools in your context that conflicts with other information in the context.
This is a more problematic version of Context Confusion: the bad context here isn’t irrelevant, it directly conflicts with other information in the prompt.
(题外话:推理模型的prompt和非推理模型的prompt是不同的。)
Think of it this way: sometimes, you might sit down and type paragraphs into ChatGPT or Claude before you hit enter, considering every necessary detail. Other times, you might start with a simple prompt, then add further details when the chatbot’s answer isn’t satisfactory. The Microsoft/Salesforce team modified benchmark prompts to look like these multistep exchanges:
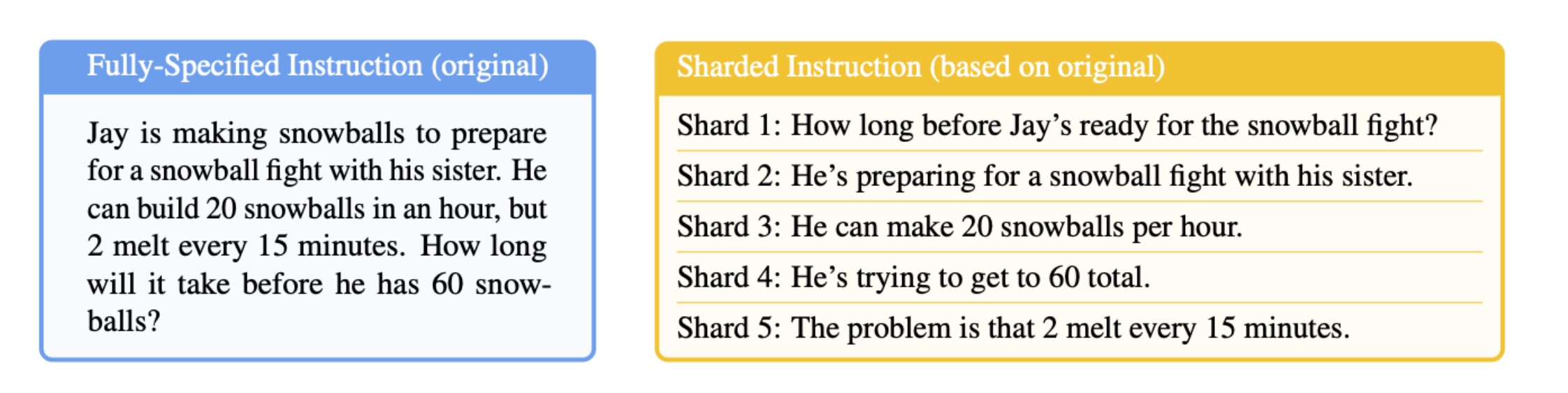
All the information from the prompt on the left side is contained within the several messages on the right side, which would be played out in multiple chat rounds.
The sharded prompts yielded dramatically worse results, with an average drop of 39%. And the team tested a range of models – OpenAI’s vaunted o3’s score dropped from 98.1 to 64.1.
The answer is Context Confusion: the assembled context, containing the entirety of the chat exchange, contains early attempts by the model to answer the challenge before it has all the information. These incorrect answers remain present in the context and influence the model when it generates its final answer. The team writes:
We find that LLMs often make assumptions in early turns and prematurely attempt to generate final solutions, on which they overly rely. In simpler terms, we discover that when LLMs take a wrong turn in a conversation, they get lost and do not recover.
也就是说,和一次性提供给llm所有信息相比,把信息分片多次提供给llm的方式效果要差,这是因为第2种方式,llm每轮会根据有限的context作出回应,这些回应可能是不正确的(因为context的信息有限)而这些回应又包含在整体context中继续提供给下一轮的llm使用,也就是llm在前面几轮的决策会影响后面的context,进而影响后面的决策。
How to Fix Your Context https://www.dbreunig.com/2025/06/26/how-to-fix-your-context.html
- RAG
Retrieval-Augmented Generation (RAG) is the act of selectively adding relevant information to help the LLM generate a better response.
用RAG来选择相关的信息,帮助llm生成better response
- Tool Loadout
Tool Loadout is the act of selecting only relevant tool definitions to add to your context.
Perhaps the simplest way to select tools is to apply RAG to your tool descriptions. This is exactly what Tiantian Gan and Qiyao Sun did, which they detail in their paper, “RAG MCP.” By storing their tool descriptions in a vector database, they’re able to select the most relevant tools given an input prompt.
选择最相关的tool,最简单的方式可以将rag作用于tool description。
- Context Quarantine隔离
Context Quarantine is the act of isolating contexts in their own dedicated threads, each used separately by one or more LLMs.
Context隔离,不同的llm用不同的context。如将任务分给多个sub agent,每个sub agent有自己独立的context window。
- Context Pruning
Context Pruning is the act of removing irrelevant or otherwise unneeded information from the context.
- Context Summarization
Context Summarization is the act of boiling down an accrued context into a condensed summary.
Context Summarization first appeared as a tool for dealing with smaller context windows. As your chat session came close to exceeding the maximum context length, a summary would be generated and a new thread would begin. Chatbot users did this manually, in ChatGPT or Claude, asking the bot to generate a short recap which would then be pasted into a new session.
- Context Offloading
Context Offloading is the act of storing information outside the LLM’s context, usually via a tool that stores and manages the data.
为agent创建short-term或long-term memory system。
Context Engineering https://blog.langchain.com/context-engineering-for-agents/
Context engineering对于agent尤其重要,因为agent通常调用很多次tool,因此agent的context通常会很长。
Agents need context to perform tasks. Context engineering is the art and science of filling the context window with just the right information at each step of an agent’s trajectory. In this post, we break down some common strategies — write, select, compress, and isolate — for context engineering by reviewing various popular agents and papers. We then explain how LangGraph is designed to support them!
We group common strategies for agent context engineering into four buckets — write, select, compress, and isolate — and give examples of each from review of some popular agent products and papers. We then explain how LangGraph is designed to support them!
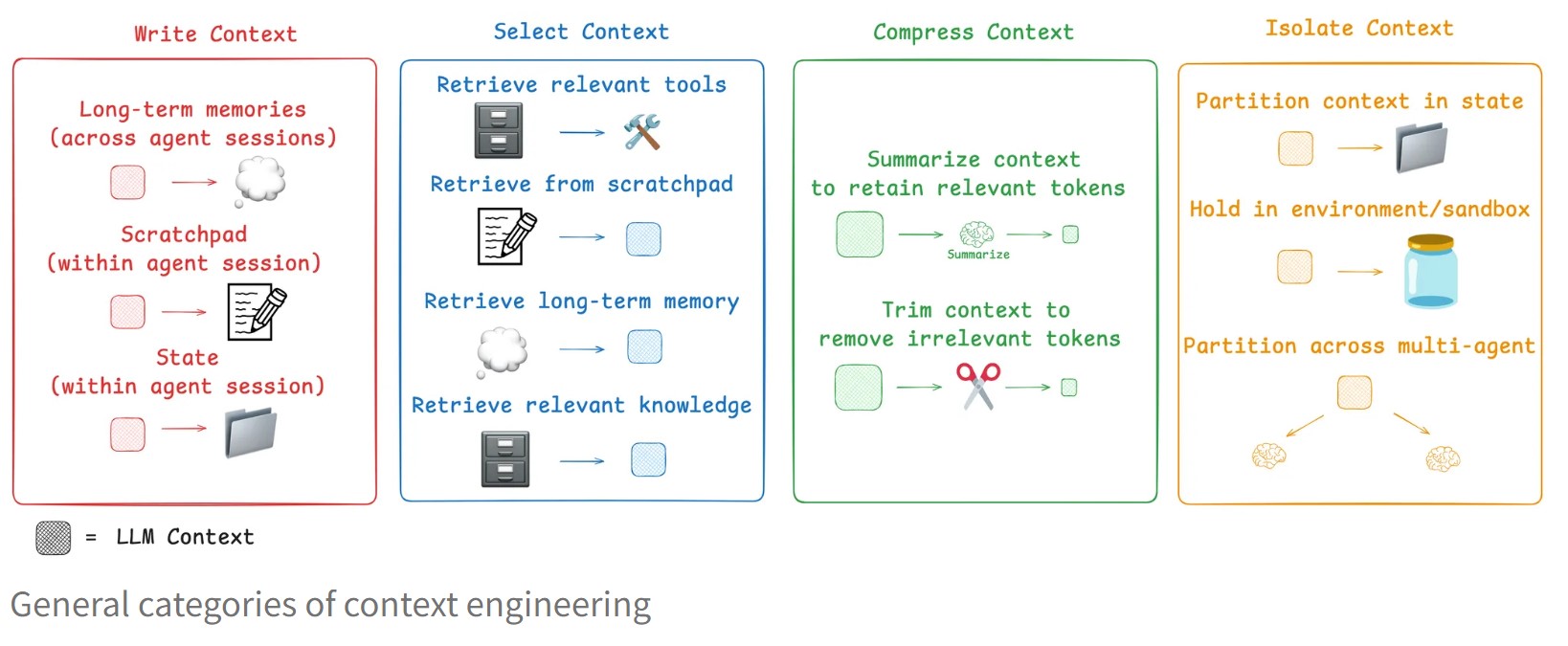
- Write
- Writing context means saving it outside the context window to help an agent perform a task.
- When humans solve tasks, we take notes and remember things for future, related tasks
像人类一样,找个草稿本(scratchpad)记下一些事情,然后用脑子(long-term memory)记住关键内容,并时刻更新memory。
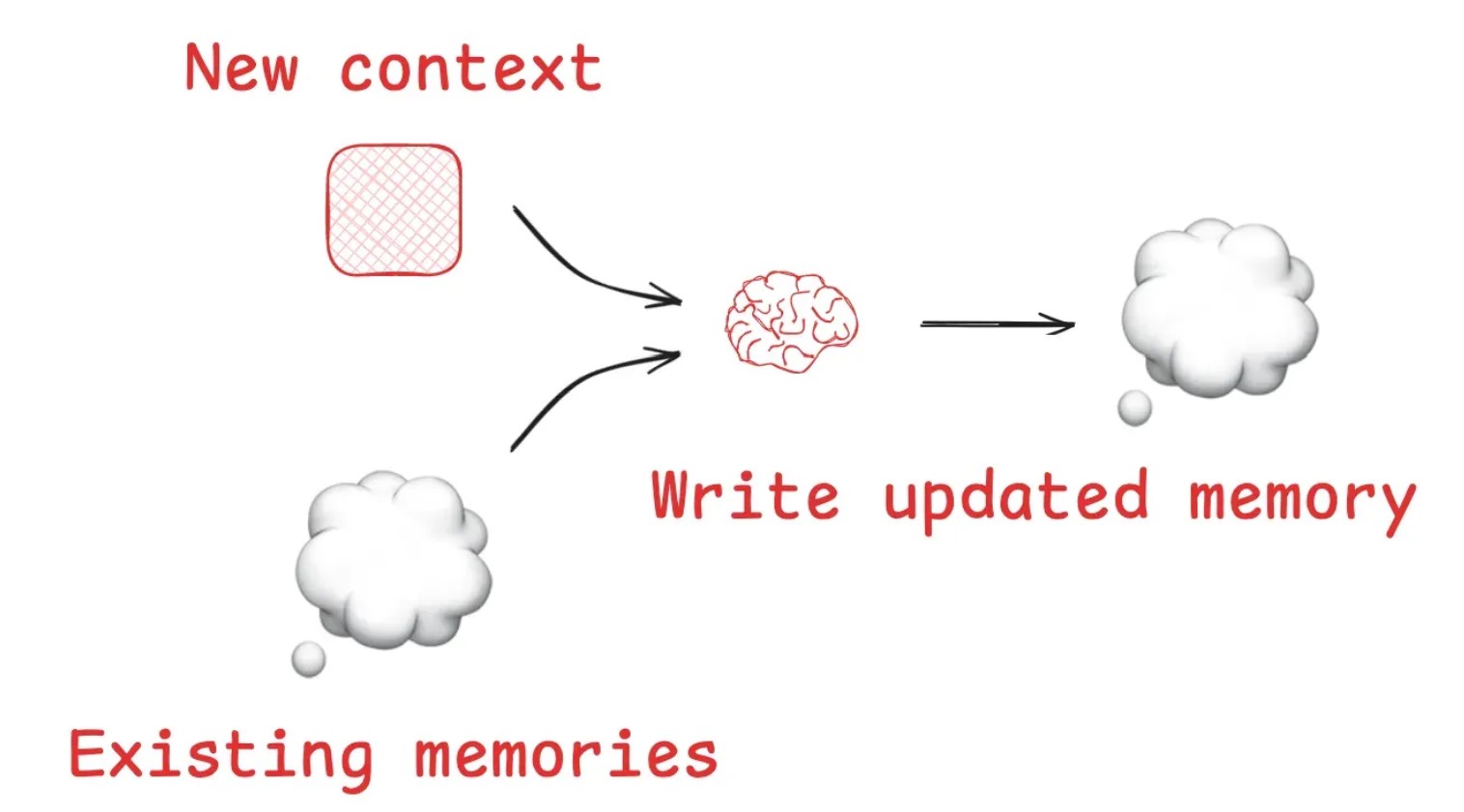
- Select
- Selecting context means pulling it into the context window to help an agent perform a task.*
从scratchpad中选最相关的
从memory中选…
从Tools中选最相关的tool
从knowledge中选最相关的,如code agent 中进行rag时,进行chunking时,每个chunk是一个完整的函数或类,而不是连续的代码。


- Compress
- *Compressing context involves retaining only the tokens required to perform a task.*
**Summarization**
- Claude Code “auto compact” https://docs.anthropic.com/en/docs/claude-code/costs
- Completed work sections https://www.anthropic.com/engineering/built-multi-agent-research-system
- Passing context to linear sub-agents https://cognition.ai/blog/dont-build-multi-agents
- Isolate
- *Isolating context involves splitting it up to help an agent perform a task.*
将一个问题分成子topic这种任务,天然适合sub agent这种架构 ,每个sub agent有自己独立的context。
Context Engineering + LangGraph
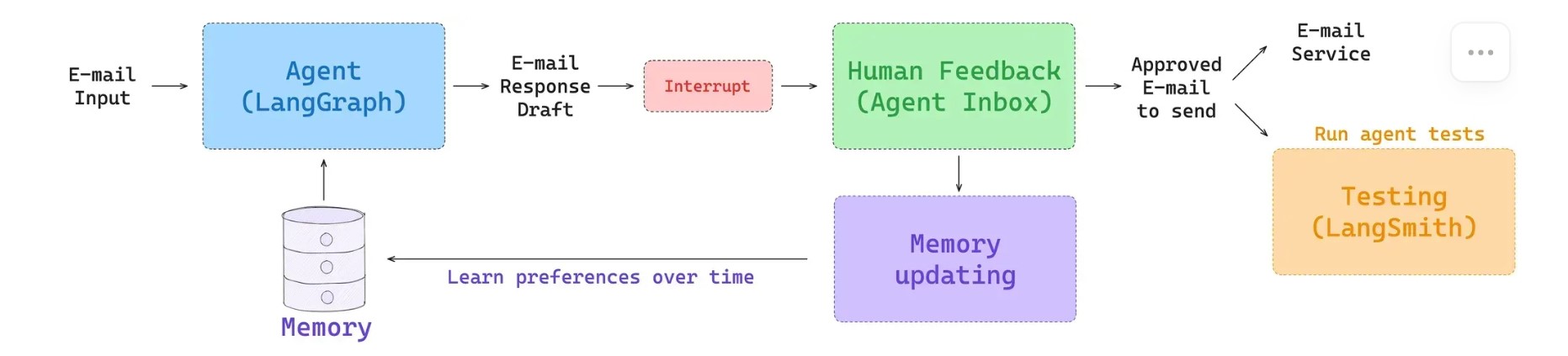
Scratchpad
- Checkpointing to persist agent state across a session ,其实就是agent state类
Memory
- Long-term memory to persist context across many sessions , memory就是持久化,可以across 不同的session,存储用户偏好之类的东西